






Вопрос мониторинга производительности - штука важная, и достаточно сложная. Может быть, не то чтобы прям сложная, но источников информации не очень много.
Однако, они есть, и один очень важный появился только что.
Расскажу по порядку свое видение вопроса.
Вот раздается звонок: "АААА. Все плохо, ваша виртуализация отстой, моя виртуальная машина тормозит".
Наши действия?
Посмотреть на цифирки счетчиков производительности, и найти источник тормозов.
1) Где искать цифирки?
2) Какие именно счетчики нас интересуют?
3) Какие значения являются плохими?
1) Где искать цифирки
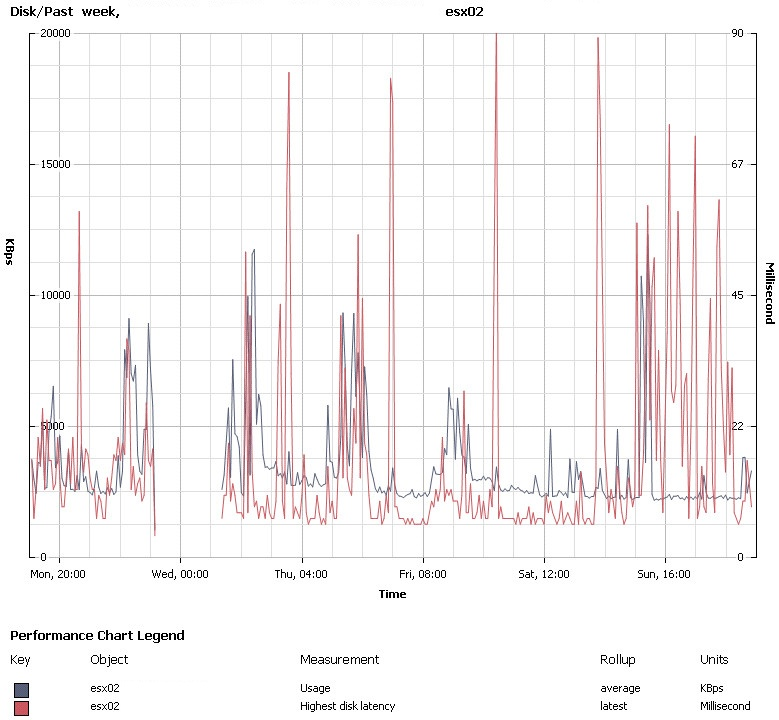
очевидно, что смотреть можно на закладке Performance в клиенте vSphere. Обратите внимание - эта закладка доступна для многих объектов, не только для хостов и виртуальных машин. Это если у нас есть vCenter. Но и без него что-то мы увидим.
Пример:
но часто более удобным и полным средством является консольная утилита esxtop. Кто использует ESX, логиньтесь по ssh и запускайте. Кто использует ESXi, вам придется скачать vMA или vSphere CLI под Linux, и оттуда запустить resxtop.
 Нажимая всякие кнопки, вы можете переключаться на разную информацию:
Нажимая всякие кнопки, вы можете переключаться на разную информацию:
c = cpu
m = memory
n = network
i = interrupts
d = disk adapter
u = disk device
v = disk VM
начиная с vSphere 4.0 Update 2 еще добавилась y - для отображения инфы про логические процессоры.
Нажав Shift+V вы оставите на экране только виртуальные машины, убрав прочие процессы гипервизора.
Нажав f, вы увидите экран выбора столбцов — далеко не вся информация отображается по умолчанию.
нажав e и введя номер из столбца GID вы развернете дерево процессов - каждой ВМ соответствует минимум три процесса (и больше для многопроцессорных ВМ, так как для каждого vCPU создается отдельный процесс).
Для дисковой подсистемы существует дополнительное средство мониторинга vscsiStats.
2) Какие именно счетчики нас интересуют?
Самые основные перечислю отдельно.
Процессор: CPU Ready. Высокие значения (больше 10% \ 200 мс на один vCPU) говорят о том, что гипервизор не выделяет для ВМ достаточно процессорного времени.
Или еще одна формулировка: процессор находится в ожидании такое количество времени за последний квант измерений. А ожидать он может:
Память: Balloon (vmmemctl) и VMkernel Swap. Если показания этих счетчиков стабильно не нулевые, значит гипервизор вытесняет гостя в файл подкачки.
Диск: Disk Queue (должна быть 0) и Latency (чем меньше чем лучше, не должна быть больше, по разным оценкам, 15-25 мс).
Полезные ссылки на описания всех доступных счетчиков.
для работы через vSphere Client:
Выбираем объект, закладка Performance, кнопка Advanced и выбираем период и счетчики. Их описание доступно тут — vCenter Performance Counters. Для полноты картины — Understanding VirtualCenter Performance Statistics.
Для работы с esxtop:
описание счетчиков — Interpreting esxtop Statistics.
Для vscsi Stats — Using vscsiStats for Storage Performance Analysis. Вспомогательное — vscsiStats и vscsiStats output in esxtop format.
3) Какие значения являются плохими?
Пороговые значения, на которые можно ориентироваться - esxtop values/thresholds!.
именно эта информацию, в удобном для восприятия виде, появилась только что.
Я прикладываю скопипастенную оттуда табличку

Эта таблица - результат усилий камрада Duncan Epping, однако эти значения еще могут изменяться, ибо автор попросил помощи у коммьюнити в наполнении ее, и уточнении пороговых значений.
4) Дополнение
Если клиент vSphere показывает нам графики, достаточно легкие для восприятия и анализа за период времени, то esxtop изначально показывает лишь цифирки за последний такт измерений. Для того, чтобы получить данные для анализа, можно опять таки строить графики на основе его данных, и тут нам приходят на помощь допсредства.
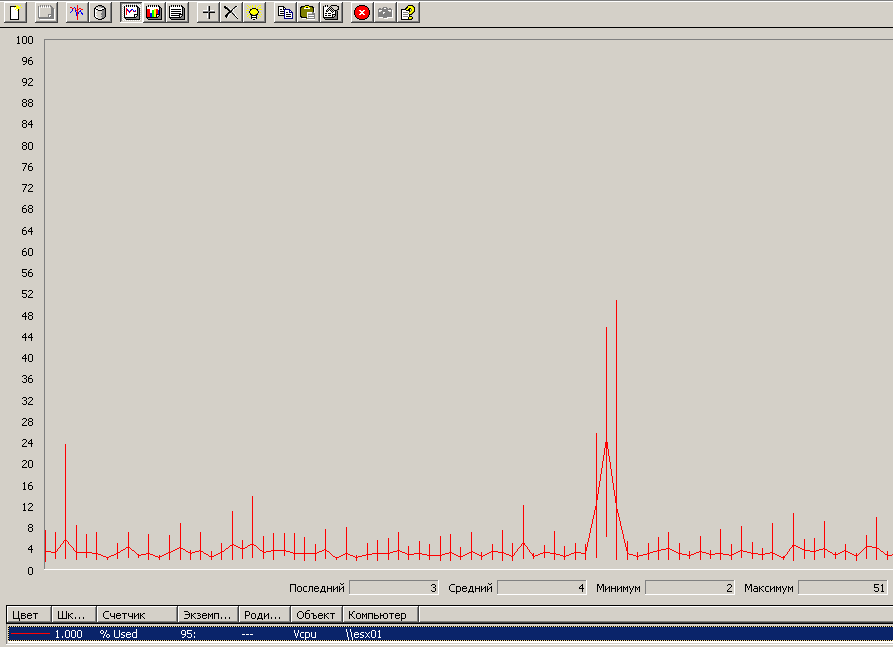
Первое, что можно использовать - perfmon.
Как - Анализ загрузки ESX.
Как сохранять в csv только желаемые данные - The Skinny on ESXTOP.
Как пользоваться esxtop в пакетном режиме (сохранить статистику за период для дальнейшего анализа), и собирать только нужные данные - How to use esxtop or resxtop in batch mode.
Второе - утилита, я так понял, для внутреннего пользования VMware (или одного из ее инженеров), под название esxplot. Скачать можно отсюда - http://www.durganetworks.com/esxplot/.
С помощью этой утилиты возможно построение наглядных графиков прямо из csv c данным от esxtop.
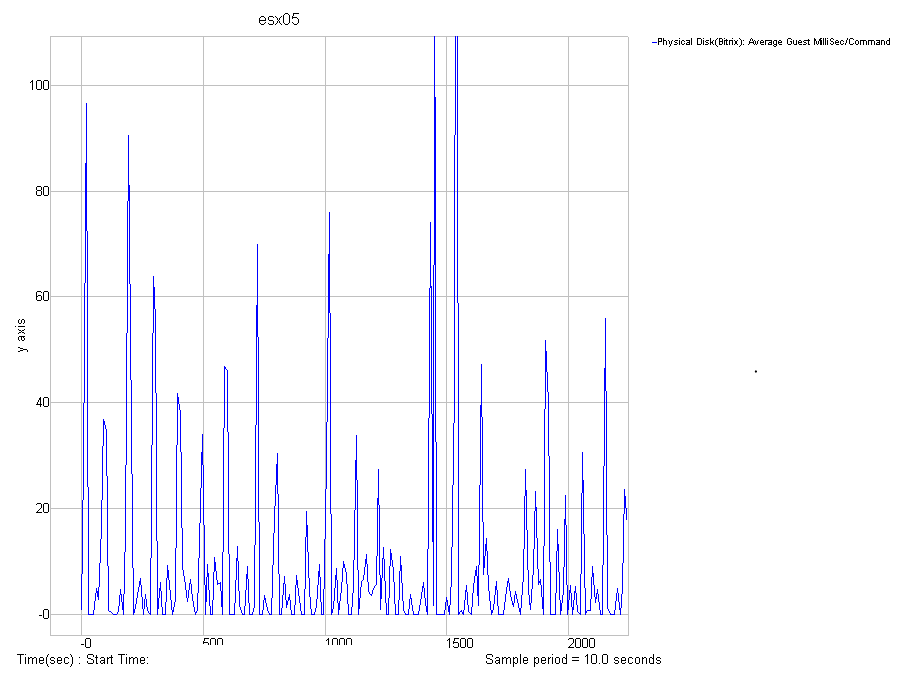 (у меня эта утилита завелась под специально установленной WinXP SP2 Eng, после установки Microsoft Visual C++ 2008 Redistributable Package (x86)). Esxplot мне понравился больше perfmon для визуализации данных.
(у меня эта утилита завелась под специально установленной WinXP SP2 Eng, после установки Microsoft Visual C++ 2008 Redistributable Package (x86)). Esxplot мне понравился больше perfmon для визуализации данных.
По поводу нюансов сбора данных для анализа в esxtop см. ESXTOP Replay and VM-Support output– AKA ‘Pain Train.
Однако, они есть, и один очень важный появился только что.
Расскажу по порядку свое видение вопроса.
Вот раздается звонок: "АААА. Все плохо, ваша виртуализация отстой, моя виртуальная машина тормозит".
Наши действия?
Посмотреть на цифирки счетчиков производительности, и найти источник тормозов.
1) Где искать цифирки?
2) Какие именно счетчики нас интересуют?
3) Какие значения являются плохими?
1) Где искать цифирки
очевидно, что смотреть можно на закладке Performance в клиенте vSphere. Обратите внимание - эта закладка доступна для многих объектов, не только для хостов и виртуальных машин. Это если у нас есть vCenter. Но и без него что-то мы увидим.
Пример:
но часто более удобным и полным средством является консольная утилита esxtop. Кто использует ESX, логиньтесь по ssh и запускайте. Кто использует ESXi, вам придется скачать vMA или vSphere CLI под Linux, и оттуда запустить resxtop.
c = cpu
m = memory
n = network
i = interrupts
d = disk adapter
u = disk device
v = disk VM
начиная с vSphere 4.0 Update 2 еще добавилась y - для отображения инфы про логические процессоры.
Нажав Shift+V вы оставите на экране только виртуальные машины, убрав прочие процессы гипервизора.
Нажав f, вы увидите экран выбора столбцов — далеко не вся информация отображается по умолчанию.
нажав e и введя номер из столбца GID вы развернете дерево процессов - каждой ВМ соответствует минимум три процесса (и больше для многопроцессорных ВМ, так как для каждого vCPU создается отдельный процесс).
Для дисковой подсистемы существует дополнительное средство мониторинга vscsiStats.
2) Какие именно счетчики нас интересуют?
Самые основные перечислю отдельно.
Процессор: CPU Ready. Высокие значения (больше 10% \ 200 мс на один vCPU) говорят о том, что гипервизор не выделяет для ВМ достаточно процессорного времени.
Или еще одна формулировка: процессор находится в ожидании такое количество времени за последний квант измерений. А ожидать он может:
- процессорных ресурсов (например, слишком много ВМ на этом ядре работает, или ВМ уперлась в назначенный ей limit).
- памяти (если память не успевает отдать данные достаточно быстро).
- диск (если данные нужно с диска загрузить). В последнем случае вас интересует значение счетчика CPU Wait - CPU Idle, эта разность должна быть не более пары десятков мс (это latency). подробности см. тут.
Память: Balloon (vmmemctl) и VMkernel Swap. Если показания этих счетчиков стабильно не нулевые, значит гипервизор вытесняет гостя в файл подкачки.
Диск: Disk Queue (должна быть 0) и Latency (чем меньше чем лучше, не должна быть больше, по разным оценкам, 15-25 мс).
Полезные ссылки на описания всех доступных счетчиков.
для работы через vSphere Client:
Выбираем объект, закладка Performance, кнопка Advanced и выбираем период и счетчики. Их описание доступно тут — vCenter Performance Counters. Для полноты картины — Understanding VirtualCenter Performance Statistics.
Для работы с esxtop:
описание счетчиков — Interpreting esxtop Statistics.
Для vscsi Stats — Using vscsiStats for Storage Performance Analysis. Вспомогательное — vscsiStats и vscsiStats output in esxtop format.
3) Какие значения являются плохими?
Пороговые значения, на которые можно ориентироваться - esxtop values/thresholds!.
именно эта информацию, в удобном для восприятия виде, появилась только что.
Я прикладываю скопипастенную оттуда табличку
Эта таблица - результат усилий камрада Duncan Epping, однако эти значения еще могут изменяться, ибо автор попросил помощи у коммьюнити в наполнении ее, и уточнении пороговых значений.
4) Дополнение
Если клиент vSphere показывает нам графики, достаточно легкие для восприятия и анализа за период времени, то esxtop изначально показывает лишь цифирки за последний такт измерений. Для того, чтобы получить данные для анализа, можно опять таки строить графики на основе его данных, и тут нам приходят на помощь допсредства.
Первое, что можно использовать - perfmon.
Как - Анализ загрузки ESX.
Как сохранять в csv только желаемые данные - The Skinny on ESXTOP.
Как пользоваться esxtop в пакетном режиме (сохранить статистику за период для дальнейшего анализа), и собирать только нужные данные - How to use esxtop or resxtop in batch mode.
Второе - утилита, я так понял, для внутреннего пользования VMware (или одного из ее инженеров), под название esxplot. Скачать можно отсюда - http://www.durganetworks.com/esxplot/.
С помощью этой утилиты возможно построение наглядных графиков прямо из csv c данным от esxtop.
По поводу нюансов сбора данных для анализа в esxtop см. ESXTOP Replay and VM-Support output– AKA ‘Pain Train.